
2023 has been a pretty wild year in machine learning.
From ChatGPT taking over jobs and news headlines, to diffusion models producing terrifying videos of celebrities eating spaghetti… what’s clear is that along with the fun, funny, and mind-expanding uses of AI and machine learning, there are many problems that come with it.
We talk about AI a lot at Anchor Line and Saltwater, and one of the obvious questions we ask ourselves frequently, is what does AI mean for the future of video and animated content? How can we both protect ourselves and our clients, and also harness the positive aspects of it to make our work better and our processes more efficient without minimizing our human creativity?
Diffusion models are both amazing and immensely controversial with people questioning if it’s ethical to have AI “learn” from massive dumps of images (original photography, art, etc.), often protected by copyright, without the permission of the creator.
Controversy aside, one could argue that the genie is already out of the bottle, as major players like Adobe are already implementing AI into their software, leaving us no choice but to ride the wave (along with improving, refining, and potentially regulating)… rather than drown under it.

How do AI diffusion models work?
Diffusion models learn by taking an existing image, let’s say a photo of an adorable hamster, and then slowly turning that image into “noise” over time. By turning the hamster image into noise, the computer is then able to learn how to arrange that noise to compile its own image of a hamster. After watching hundreds of hamsters get turned into noise patterns, when asked to make a hamster, the computer starts organizing noise to generate its own “unique” hamster, which will always be different based on the various patterns of noise it generates.
When you type in a prompt and see an image generated in seconds, it can feel like magic.

As a video production company, Diffusion AI has made building video sets faster than ever for us. When working in 3D to produce product renders, historically it would take time to build an eye-catching environment for the product to exist within, but now we can generate multiple options for the client to review in just minutes, rather than kitbashing assets for hours.
If we filmed in location and later the client isn’t feeling it or we need to modify the background, we can simply give the AI a frame from the scene and request alternative options. From there, we can use AI assisted rotoscoping to modify the scene or place the talent into an entirely new location with minimal effort.

A huge time saver for us has been building what’s known as “clean plates” or just painting out logos or clutter from shots. Previously this would require going into Photoshop and slowly painting out the distracting elements in the scene frame by frame, or taking time to manually build a clean plate to use in the shot.
Adobe’s Content Aware Fill has improved over the years, but it can be hit or miss. Using tools like Stable Diffusion, I can put a frame from the shot into Image2Image (where it uses an image as a reference) and I can add a text description on how the new shot should look, and it will produce a series of different options. If there are logos, cables, or other elements I need to remove from the shot, there’s an “inpainting” tool that can take text prompts and fix masked areas. Now Photoshop has incorporated Adobe Firefly (their own diffusion AI) where you can mask out an area, type a prompt on what you’d like to fix or change (Generative Fill), and you’ve got an option within seconds.

Another amazing asset that can be used with tools like StableDiffusion is “ControlNet” which can take doodles, depth maps, or outlines of what you’d like to see and then turn them into photos, or any other medium you may need. We found this is particularly useful for building quick, polished storyboards. When in the past the director might doodle stick figures to determine shot composition, and then hired a storyboard artist to elevate those doodles into storyboards to share with a client, if time or budget do not allow for professional boards, we have a workable option that can be completed in minutes.
When scouting production locations, we can also take photos of potential sets and then feed those into ControlNet with various text prompts to instantly see how the set will look dressed up in different ways and with different lighting designs.
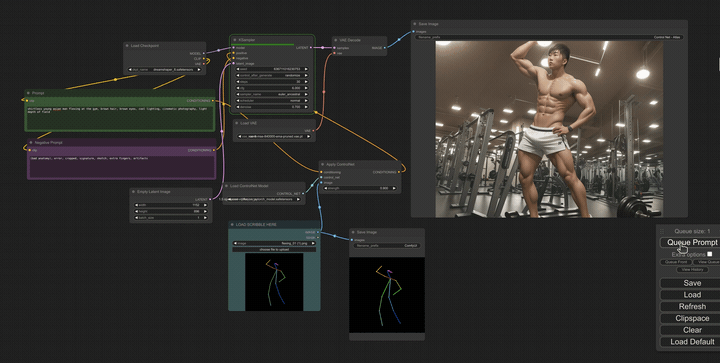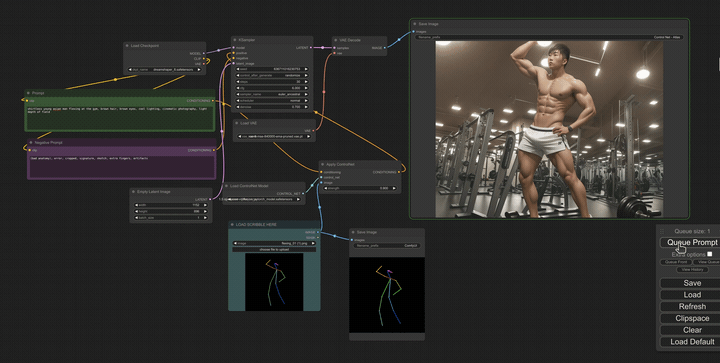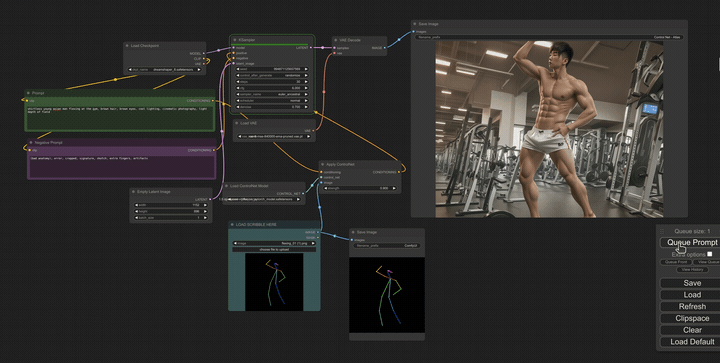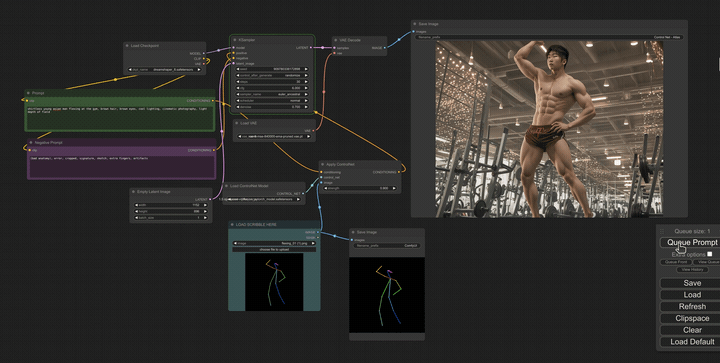
In conclusion…
These tools have been evolving at an insane speed since we first saw them rendering eerie and uncanny people with multiple arms last year. They can now create realistic portraits where even my discerning eye often can’t tell the difference between what’s a photo and what’s AI.
The next big leap appears to be full video. At this point, text2video produces blurry messes and freakish looking people, but with how quickly image diffusion progresses, I expect video to do the same.
It’s a little scary seeing just how much machine learning has been shaking up the industry, but I do believe these tools won’t replace us, but rather enable us to achieve a lot more in much less time.
Have questions about AI, Diffusion, or how to use it to enhance your video edits rather than stifle them? Reach out to us today!